
On Data
I’m not a DBA, I’m also not a data architect. But I spend a lot of my time in databases; so this is written from a developers perspective.
The three stages of data
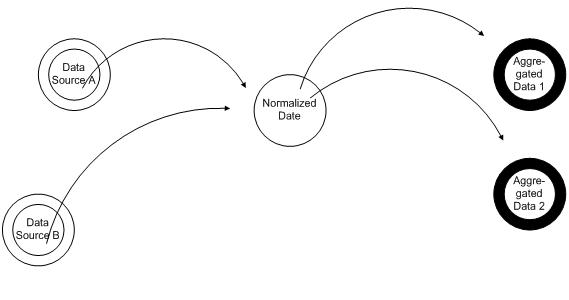
It seems that data lives in three stages, first the data is raw, it then gets normalized and finally Aggregated.
Raw data tends to be de-normalized and segregated by source, and gets updated. The source of this data could be a data feed, a service, user activity on the site, or sensors. This data tends to make up the majority of the records in databases that you’ll find in applications. And in many cases one of the data sources will be the system you are implementing.
The second stage of data, the Normalized Data, is where it gets normalized. This is where the different data sources come together and the data gets normalized. This is where records from different sources get linked together by business rules and where mappings occur between enumerations of different sources.
The third stage of the data, the Summarized Data, is where data gets summarized and molded for consumption. An example of this would be when title, first name, last name get combined into a display name. This is where the data for an account is summarized or content ratings get computed.
There once was a database in a company far, far away ..
Most systems will have examples of all of these concepts, but the concepts are comingled in the database. A common pattern tends to be that people take their first data feed and make that the database. The application retrieves the data trough stored procedures that aggregate the data.
Then a second data source comes along.
The second data source will offer some data that the first data source doesn’t offer; so the data model gets augmented to support the second source. A few columns get added to the existing model to support the new data and the new data gets merged in with the original data. The procedures get updated to account for the changes in the model, and the things get up and running.
So far so good, or at least so it seems. There was something lost; the system is now in a transient stage. Depending on the order of the arrival of the data sources the behavior would be different. The system has also an all or nothing approach, when a data source is added the entire system needs to be aware of this. The data source will impact the procedures that retrieve data for the UI as well as impacting the data load for the initial source.
So let’s look a bit further in the life cycle of the application. More sources are added, more data is added, there are more users and they are complaining that the system is getting “slow”. Load drives the next generation changes, the summarization of data. Some complex common queueries get precomputed, some times in their own tables, some times as columns added to existing tables. The high usage areas of the application get updated to use the new queueries.
And this brings us to the point where most applications end up, with a database in a transient state and production support DBAs getting midnight calls as the order of data sources manage to get themselves in a new and interesting state.
Conclusion
Most systems will fall in a range between a segregated approach and an integrated approach. And of the systems that I’ve worked on the more segregated systems were the ones that were easiest to work on. Some of the benefits that resulted from this segregation were as follows.
- All normalized data and aggregated data could be deleted and recomputed. When the business logic for aggregation on normalization changed it had only change in one place and there was no “legacy” data.
- There less code, although much more data. If any information had to be computed it was precomputed and stored in a table. The procedures to retrieve data were simple joins and no data manipulation was needed. In the transition from a classic system to a segregated system we reduced the lines of sql by more than 60%.
- The system is fast, everything is a simple select with a few possible joins
- The system was easy to learn and fairly self documenting. Each summary table has procedure(s) that populates it, the data retrieval procedures build upon the summary tables.
- Easy to verify, the system can be inspected in each of the stages to you only need to verify small pieces of logic at a time.
As for the drawbacks
- This system will increase data size between X 2 and X 5, table lengths are not impacted. All data is copied once to the normalization tables, and possibly to the summary tables
- The system does not accommodate systems with frequent updates. Each update cascades to the normalized and summary tables. It is ideal for systems that have a concept such as batch or nightly imports.
Considering the reduction in the cost of redundant storage, and the advent of big table solutions like seen in many could solutions the major deficit of the solution (storage) will be negated. The secondary deficit is still applicable.
